
{kind=link}
SolidityBench by IQ was launched as the primary benchmark to judge LLMs in Solidity code technology. Out there on Hugging Face, it options two revolutionary benchmarks, NaïveJudge and HumanEval for Solidity, designed to evaluate and rank the proficiency of AI fashions in producing good contract code.
Developed by IQ's BrainDAO as a part of its upcoming IQ Code suite, SolidityBench is used to refine its personal EVMind LLMs and examine them to general-purpose and community-created fashions. IQ Code goals to supply AI fashions appropriate for producing and auditing good contract code, assembly the rising want for safe and environment friendly blockchain functions.
As IQ mentioned forexcryptozoneNaïveJudge presents a novel method by tasking LLMs with implementing good contracts based mostly on detailed specs derived from audited OpenZeppelin contracts. These contracts represent a benchmark for accuracy and effectivity. The generated code is evaluated in opposition to a reference implementation utilizing standards comparable to practical completeness, adherence to Solidity finest practices and safety requirements, and optimization effectiveness.
The analysis course of depends on superior LLMs, together with totally different variations of OpenAI's GPT-4 and Claude 3.5 Sonnet as neutral code reviewers. They consider code based mostly on rigorous standards, together with implementation of all key options, dealing with of edge instances, error dealing with, acceptable use of syntax, and the general construction and maintainability of the code. code.
Optimization concerns comparable to fuel effectivity and storage administration are additionally evaluated. Scores vary from 0 to 100, offering a complete evaluation of performance, safety and effectiveness, reflecting the complexity {of professional} good contract improvement.
Which AI fashions are finest for creating sturdy good contracts?
Benchmarking outcomes confirmed that OpenAI's GPT-4o mannequin achieved the very best general rating of 80.05, with a NaïveJudge rating of 72.18 and HumanEval go charges for Solidity of 80%. at go@1 and 92% at go@3.
Apparently, new reasoning fashions like OpenAI's o1-preview and o1-mini had been crushed to first place, with scores of 77.61 and 75.08, respectively. Fashions from Anthropic and 10 with 52.54.
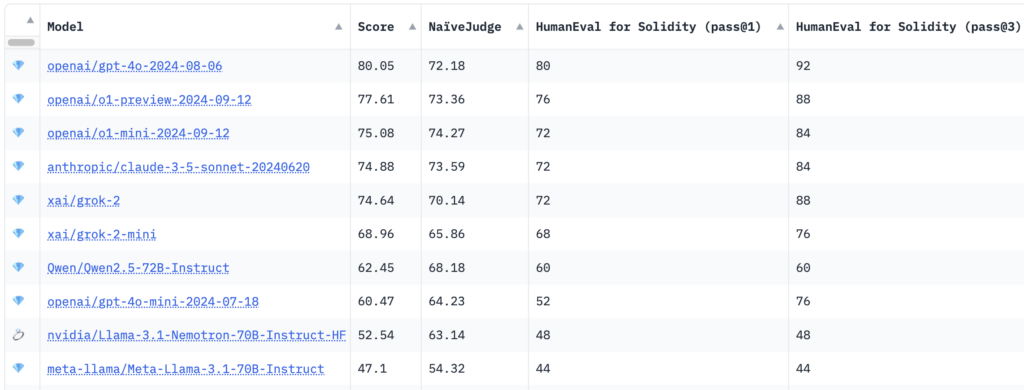
In line with IQ, HumanEval for Solidity adapts OpenAI's authentic HumanEval benchmark from Python to Solidity, encompassing 25 duties of various problem. Every job consists of corresponding exams suitable with Hardhat, a well-liked Ethereum improvement surroundings, facilitating correct compilation and testing of the generated code. The analysis metrics, go@1 and go@3, measure the success of the mannequin on preliminary makes an attempt and throughout a number of trials, offering perception into accuracy and problem-solving capabilities.
Objectives of Utilizing AI Fashions in Sensible Contract Growth
By introducing these benchmarks, SolidityBench seeks to advance AI-assisted good contract improvement. It encourages the creation of extra refined and dependable AI fashions whereas offering builders and researchers with priceless insights into the present capabilities and limitations of AI in Solidity improvement.
The benchmarking toolkit goals to advance IQ Code's EVMind LLMs and likewise units new requirements for AI-assisted good contract improvement within the blockchain ecosystem. The initiative hopes to handle a important want within the trade, the place demand for safe and environment friendly good contracts continues to develop.
AI builders, researchers, and lovers are invited to discover and contribute to SolidityBench, which goals to drive steady enchancment of AI fashions, promote finest practices, and advance decentralized functions.
Go to the SolidityBench leaderboard on Hugging Face to be taught extra and begin evaluating Solidity technology fashions.